Introduction
It was 12 PM on a weekday - our peak traffic hour. I was one of the three engineers at a small fintech startup. Suddenly, our entire platform went dark. No metrics, no logs, no alerts - just angry customers and a silent monitoring dashboard. We were in limbo and no idea what failed. After 45 minutes of blind debugging and a full system restart, we were back online. That day taught me that fault tolerance isn’t luxury engineering - it’s survival. We had no error tracking, no observability, no automated recovery - nothing.
The incident cost us more than just 45 minutes. We lost customer trust, faced regulatory scrutiny, and spent the next three months rebuilding our entire infrastructure. But the real lesson wasn’t about the technology - it was about understanding that fault tolerance is the difference between a sustainable business and a ticking time bomb.
The cost of downtime varies dramatically by scale. For Stripe, an outage costs approximately $450,000 per minute in lost transaction fees alone. Shopify’s Black Friday downtime could mean millions in lost merchant sales within hours. Amazon loses $220,000 per minute when their site goes down. But for small startups like ours, downtime isn’t just about money - it’s existential. A single prolonged outage can destroy customer trust permanently, trigger contract penalties, and invite competitors to poach your clients.
What I learned from that painful day, and from years of building resilient systems since, is that fault tolerance isn’t about preventing all failures - it’s about building systems that bend without breaking. This article shares industry-proven patterns from Google, AWS, Netflix, and other tech giants that have turned fault tolerance from an aspiration into a science. The Industry-Standard Pillars of Fault Tolerance
Based on frameworks from Google SRE, AWS Well-Architected, Netflix’s resilience principles, and lessons from countless production systems, fault-tolerant architectures rest on six fundamental pillars. These aren’t theoretical constructs - they’re battle-tested patterns that keep the internet running.
Pillar 1: Redundancy & High Availability
The Core Principle
Redundancy eliminates single points of failure through strategic duplication. It’s the foundation of fault tolerance, but implementing it effectively requires understanding the trade-offs between consistency, availability, and cost.
The most basic form is multi-instance deployments across availability zones. Netflix pioneered this approach at scale, running every service across at least three AWS availability zones. When AWS US-East-1 experienced a major outage in 2011, Netflix customers barely noticed - their redundant deployments in other zones picked up the load seamlessly.
Key Implementation Strategies:
Multi-zone deployments: Run services across 3+ availability zones minimum
Active-active configurations: Stripe processes payments across zones simultaneously for sub-second failover
Active-passive setups: Simpler operations for teams that value consistency over speed
Geographic distribution: Uber's driver matching runs in 10+ independent regions
Geographic distribution takes redundancy global, but it requires careful architectural decisions. Facebook’s multi-datacenter architecture replicates user data across continents, serving their global user base with local latency. The challenge isn’t just having multiple locations - it’s ensuring they can operate independently when network partitions occur.
Database Replication Approaches:
PostgreSQL streaming replication for near-real-time disaster recovery
MySQL Group Replication for multi-primary write scaling
Redis Sentinel for automated cache failover
Cassandra or DynamoDB for globally distributed data
Essential Tools and Services:
Container orchestration: Kubernetes ReplicaSets, Docker Swarm
Managed databases: AWS Multi-AZ RDS, Google Cloud SQL, Azure Database
Load balancing: AWS ELB, HAProxy, NGINX Plus, Cloudflare Load Balancing
The key lesson from years of building redundant systems: start with managed services that handle replication complexity, then customize when you hit their limitations. Your database replication strategy will ultimately determine your uptime ceiling.
Pillar 2: Fault Detection & Observability
You Can’t Fix What You Can’t See
This simple truth becomes painfully clear during outages when you’re debugging blind. Modern observability goes beyond traditional monitoring, providing deep visibility into system behavior through three complementary lenses.
The Three Pillars of Observability:
Metrics - Your System’s Vital Signs
Prometheus revolutionized metrics collection with its pull-based model and powerful query language. Datadog and New Relic offer managed solutions with sophisticated analytics. CloudWatch serves as the foundation for AWS-based architectures.
Spotify uses these tools to monitor over 200 microservices, tracking everything from request rates to garbage collection pauses. The key insight: focus on percentiles rather than averages. Your p99 latency tells you what your unluckiest users experience, while averages hide the pain.
Logs - Your System’s Black Box
Industry standards: ELK Stack (Elasticsearch, Logstash, Kibana), Splunk, Grafana Loki
Key requirement: Structured logging with correlation IDs across services
Slack's achievement: 5-minute incident response through searchable logs
Common mistake: Unstructured logs that become expensive noise
Traces - Following the Request Journey
Distributed tracing reveals the hidden complexity of microservice interactions. Tools like Jaeger and Zipkin, inspired by Google’s Dapper paper, visualize request flow through services. AWS X-Ray provides native tracing for AWS services. GitHub uses distributed tracing to identify bottlenecks, preventing minor slowdowns from cascading into site-wide outages.
Error Tracking: Your Early Warning System
Error tracking deserves special attention - it’s what we desperately needed during our outage. Sentry has become the industry standard, capturing exceptions with full stack traces and grouping similar errors intelligently.
Where to integrate error tracking:
Application layer - catch unhandled exceptions
API gateways - monitor failed requests and status codes
Background jobs - track task failures and retry patterns
Frontend - capture JavaScript errors and user rage clicks
Tool ecosystem:
Sentry: Airbnb catches 90% of bugs before user reports
Rollbar: Strong DevOps workflow integrations
Bugsnag: Mobile and frontend specialist
Airbrake: Deep language-specific integrations
Google’s Four Golden Signals provide the framework for measurement: Latency (response time distribution), Traffic (request patterns), Errors (failure rates by type), and Saturation (resource utilization). These signals work together - high saturation precedes latency increases, which trigger errors.

Pillar 3: Automated Recovery & Self-Healing
When Humans Can’t Keep Up
Human intervention doesn’t scale. When you have 5 servers, you can SSH in and fix things. When you have 500, manual intervention means certain death. Self-healing systems detect failures and recover automatically, often before users notice problems.
Circuit Breakers: Stop the Cascade
Circuit breakers prevent cascade failures by monitoring downstream service health. When failures spike, the circuit “opens,” returning fallback responses instead of propagating failures upstream. Netflix’s Hystrix established the pattern, though modern alternatives like Resilience4j, PyBreaker, and go-breaker have taken over.
Netflix famously used this pattern during AWS outages - when recommendation services failed, users still saw cached viewing history. The circuit breaker prevented the failure from spreading to core streaming functionality.

Smart Recovery Patterns:
Retries with exponential backoff: Discord achieves 99.99% message delivery
Health checks that actually work: Include dependency checks, not just "200 OK"
Auto-scaling on business metrics: Scale on checkout time, not just CPU
Automatic failover: Shopify's zero-downtime Black Friday database switches
Kubernetes revolutionized health checking with liveness and readiness probes. Liveness probes restart unhealthy containers, while readiness probes prevent traffic from reaching containers that aren’t ready. The common mistake is shallow health checks that lie about actual service availability.
Auto-scaling Success Stories:
During Prime Day, Amazon’s auto-scaling handles 10x traffic automatically. The sophistication isn’t in the scaling itself - it’s in scaling based on business metrics rather than infrastructure metrics. Scale when customer experience degrades, not when servers get busy.
Deployment strategies for recovery:
Rolling deployments with automatic rollback on error spike
Blue-green deployments for instant version switching
Canary deployments testing on 1% of traffic first
The golden rule: if deployment requires a war room, you’re doing it wrong.
Pillar 4: Graceful Degradation
The Art of Partial Failure
Perfect availability is impossible, but complete failure is unacceptable. Graceful degradation ensures that when components fail, the system continues serving core functionality.
Twitter’s approach during traffic spikes became the textbook example. They disable trending topics, suggestions, and analytics while keeping core tweeting alive. Users might not get the full experience, but they can still communicate - which is Twitter’s core value proposition.
Feature Flags as Circuit Breakers:
Tools: LaunchDarkly, Split.io, Optimizely, Unleash
Implementation: Every feature ships with an off switch
Business value: Turn off features, not revenue streams
Intelligent Fallback Strategies:
LinkedIn switches to cached newsfeeds when recommendation engines struggle. GitHub disables repository search during high load but keeps code operations running. The principle is simple: stale data beats no data, and partial functionality beats complete outage.
Priority-Based Load Management:
Uber’s system perfectly demonstrates intelligent prioritization:
P0 (Core): Rider-driver matching - must never fail
P1 (Important): Surge pricing - can show cached values
P2 (Nice-to-have): Social features - first to be disabled
Load shedding takes this further by explicitly rejecting requests when approaching capacity. Google’s approach is to fail fast with proper error codes rather than accept requests that will timeout. Facebook’s proxy layers shed load at the edge, protecting core services from overload.

Pillar 5: Chaos Engineering & Testing
Breaking Things on Purpose to Build Confidence
The best way to avoid surprises in production is to create them intentionally. Netflix didn’t just pioneer chaos engineering - they made it a competitive advantage.
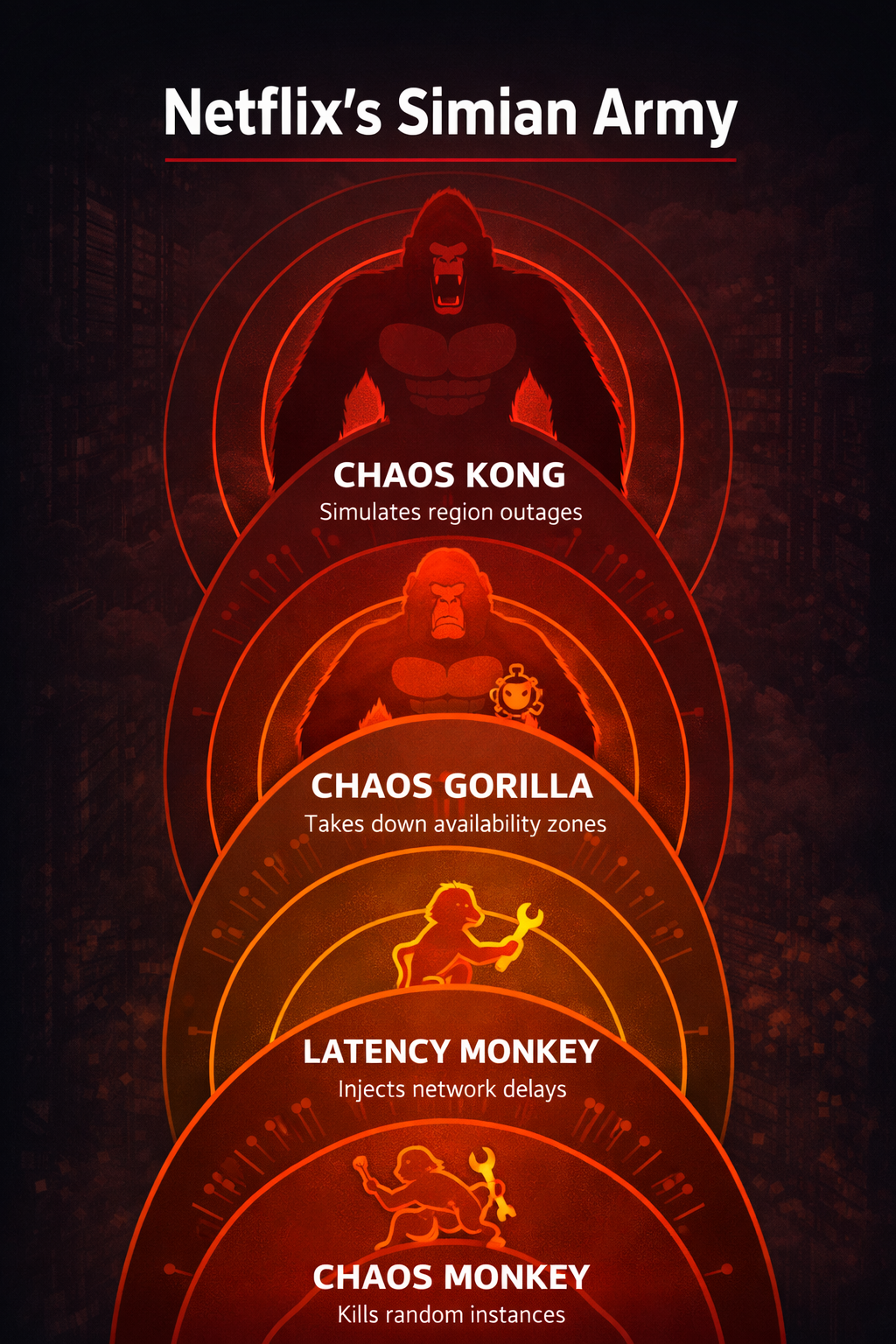
The Legendary Simian Army:
Netflix’s tools became industry legend:
Chaos Monkey: Randomly kills instances (runs continuously in production!)
Chaos Gorilla: Simulates availability zone failures
Chaos Kong: Takes down entire regions
Latency Monkey: Injects network delays to find timeout issues
The psychological impact is profound. When engineers know Chaos Monkey will kill their instances randomly, they design for failure from the start. It’s not about the tool - it’s about the mindset shift.
Modern Chaos Engineering Ecosystem:
The practice has democratized with tools like Gremlin (chaos-as-a-service), LitmusChaos (Kubernetes-native), Azure Chaos Studio, and AWS Fault Injection Simulator. What was once Netflix’s secret weapon is now table stakes for reliable systems.
Beyond Chaos: Comprehensive Testing
Load testing: JMeter, Gatling, k6 - test 10x your peak traffic
Game Days: Amazon's weekly failure exercises
DiRT exercises: Google's multi-day disaster simulations
Synthetic monitoring: Continuous production testing with Pingdom, Datadog Synthetics
Facebook’s synthetic monitoring discovered cache dependencies that would have caused cascading failures. The investment in testing transforms real incidents from panic-inducing crises into routine operations.
Industry Adoption Milestone: AWS added chaos engineering to Well-Architected Framework (2020), signaling that this is no longer optional for serious systems. Financial services now require chaos testing for regulatory compliance.
Pillar 6: Data Integrity & Durability
Protecting What Can’t Be Replaced
Systems can be rebuilt in hours. Lost data is gone forever. This fundamental truth drives every decision about data protection.
The GitLab Wake-Up Call (2017):
GitLab had five backup strategies:
Periodic PostgreSQL dumps
Disk snapshots
Continuous replication
Offsite backups
S3 uploads
All five were silently failing. Only luck and a random delayed replica prevented total data loss. The lesson: untested backups aren’t backups - they’re hopes and prayers.
Modern Backup Strategies:
Successful backup strategies balance multiple concerns:
Automation: Not cron jobs, but orchestrated workflows
Geographic distribution: Single region equals single point of failure
Testing: Monthly restore drills minimum
Retention: Balance compliance requirements with storage costs
Data Backfilling: Your Recovery Lifeline
When things go wrong, backfilling saves the day. Stripe’s infrastructure processes billions of records during schema migrations without downtime. The key components:
Idempotent operations that can safely run multiple times
Progress tracking with resumable checkpoints
Rate limiting to avoid self-inflicted DoS
Verification passes to ensure consistency
Replication Strategy Selection:
Different consistency requirements demand different approaches:
Synchronous replication (PostgreSQL synchronous standby): Best for financial transactions where zero data loss is non-negotiable, accepting higher write latency as the trade-off.
Asynchronous replication (MySQL async): Ideal for read-heavy workloads where performance matters more than losing a few seconds of transactions.
Multi-region active-active (Cassandra, DynamoDB): Perfect for global applications requiring local latency and tunable consistency.
Industry Durability Standards:
AWS S3: 99.999999999% (11 nines) durability
Stripe: Payment data in 5 global data centers
GitHub: Point-in-time recovery saved them from corruption
Your minimum: 3 copies, 2 locations, 1 offsite
Case Studies: Learning from Major Outages
The most valuable lessons come from studying failures, especially those that affected millions of users and cost millions of dollars.
AWS S3 Outage (2017)
A simple typo in a command took down S3’s control plane for four hours, affecting thousands of services that depended on it. An engineer’s debugging command accidentally removed servers faster than expected, cascading into a complete subsystem restart.
The lessons were profound. Blast radius limitation through service isolation could have contained the impact. Even “simple” changes need gradual deployment and validation. Most critically, the incident revealed hidden dependencies between control plane and data plane operations that many services hadn’t considered. Companies learned to architect for S3 unavailability despite its legendary reliability.
GitHub Outage (2018)
A network partition caused a split-brain scenario in GitHub’s database cluster, leading to 24 hours of degraded service. Automated failover systems made decisions that seemed correct locally but were globally inconsistent.
The incident challenged assumptions about automated recovery. Sometimes manual intervention by experienced engineers produces better outcomes than automated systems. Partition-tolerant architectures must handle split-brain scenarios explicitly. Comprehensive runbooks and practiced disaster recovery procedures proved more valuable than sophisticated automation. Cloudflare Outage (2019)
A BGP routing configuration error caused 30 minutes of global impact, taking down millions of websites. A regular expression in a firewall rule consumed excessive CPU, which cascaded into a complete service failure.
This highlighted that network-level fault tolerance is as critical as application-level resilience. Configuration management and validation must be as rigorous for infrastructure as for code. Progressive rollout of infrastructure changes, even seemingly minor ones, prevents global impact. Facebook Outage (2021)
BGP route withdrawal isolated Facebook’s entire infrastructure for over six hours. The configuration change locked engineers out of the very systems needed to fix the problem, creating a circular dependency.
The lessons were sobering. Out-of-band access mechanisms must exist for when primary systems fail. Dependencies between control systems can create failure loops. Human access during automation failures requires special consideration - Facebook engineers couldn’t even badge into buildings because the security systems depended on the failed infrastructure.
Conclusion
Fault tolerance is achievable at any scale. The fintech startup I mentioned at the beginning now processes millions of transactions daily with 99.99% availability. We didn’t achieve this overnight or with unlimited resources. We built incrementally, starting with observability and error tracking because you can’t fix what you can’t see.
The journey began with Sentry for error tracking and basic CloudWatch metrics. We added redundancy incrementally, starting with critical services. We implemented circuit breakers after studying Netflix’s patterns. We introduced chaos engineering gradually, beginning with read-only tests. Each step made the next one easier, creating a virtuous cycle of reliability.
The patterns in this article aren’t just for tech giants. Every system can benefit from redundancy, observability, and graceful degradation. The tools mentioned span from open-source solutions suitable for startups to enterprise platforms for large organizations. The key is starting somewhere and improving continuously.
Remember: the cost of fault tolerance is always less than the cost of downtime. Whether you’re protecting a small startup from extinction or ensuring a global platform’s reliability, these patterns provide a roadmap. Learn from others’ outages to prevent your own. Most importantly, accept that failures will happen and design systems that bend without breaking. That’s not pessimism - it’s engineering.